Universal Unique Identifiers (UUIDs or ObjectIds) have been standard practice in distributed environments for the last decade. As a result there has been a vast amount of research into various algorithms and strategies. This document is a brief synopsis of techniques and specification on a particular algorithm.
Generation of unique identifiers by the database has several negative implications.
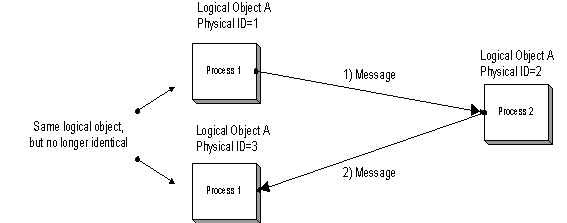
If process one passes an object to process two in a message and then process two passes that same object back to processes one, the instance of the object will be different. Process one has no consistent identity by which to determine if the objects are the same instance. This is why middleware solutions, such as CORBA, assign IORs interoperable object references.
One could call a network service or database stored procedure to create an identifier at object instantiation time. While functional, this has serious performance implications since network (and possibly database overhead) can contribute a significant latency to the generation process. Conceptually, every object that is created should have an identity. <>Some platforms provide DCE compliant generation utilities such as UUIDGEN or GUIDGEN. These utilities are not much different than calling a network service or stored procedure in that they imply significant overhead. In addition, use of these utilities couples the implication to a platform.
In order to preserve instance identity in a distributed environment
(that may or may not be based on CORBA or EJB), and to provide for the
best possible performance, this design recommends that the identifier generation
occur as a part of each application. This generation should occur at object
instantiation time, using a local implementation of the generator. This
design recommends an abstract data type (a class) which is the identifier.
Assuming a Java implementation, this design recommends that an interface,
a class, and a factory be created to support ObjectIds.
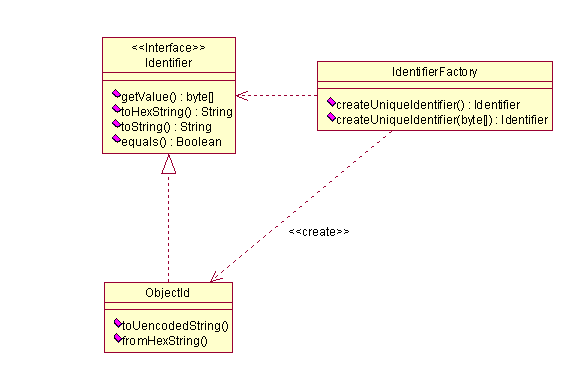
ObjectId is the class that contains the logic to generate the unique identifier. Identifier is an interface which allows for strategies of differing types of ids should the need arise. However, the strategy inforces that all ids manifest themselves as byte arrays.
Some exceptions to this may exist and should be handled individually. Similar conventions can be used in other object-oriented languages. If the language does not support object identity, conceptually, the object address can be substituted.
To provide this support the generation of object identities will be based loosely on the DCE standard for Universally Unique Identifiers (UUIDs). Java is the stated primary implementation language for the iWombat libraries. Due to this, a minor limitation is imposed in the composition of the identifier. DCE calls for the creating hosts MAC address to be embedded in the identifier. Due to an apparent limitation of Java, only the IP address can be determined in a platform independent fashion.
Due to this limitation full implementation of the DCE specification requires that MAC address must be obtained through abnormal means (not java native). Thus, for iWombat.com purposes the ObjectId class will be expecting a MACADDR environment variable be present and available to the JVM.
Resolutions to these issues are as follows:
To minimize the amount of time required in generating a value, the MAC address is initialized once and then stored as static attributes of the ObjectId. The static nature of these attributes means they are only stored once despite the number of instances created.
The generated value, being 16 bytes, is too large to fit in a primitive data type. The Java long integer data type is only 64-bits (8 bytes) long. Therefore, the generated value is stored as an array of bytes.
Identifier anOid = IdentiferFactory.getUniqueIdentifier();
Additionally, since all identifiers need to have as their root primitive a byte-array the factory can create a new Identifier from an existing byte-array:
Identifier anOid = IdentiferFactory.getUniqueIdentifier(myBytes);
The equals() method allows one to test equality between two objects. The Identifier may be compared to any other object for equality. If the object that the Identifier is being compared to is not of the same class, the result will be false. If the second object being compared is another GUID, then the equality test is double-dispatched to the second GUID in order to preserve encapsulation. Equality may be tested in the following fashion:
if( anIdentifer.equals(anObject) ) {
//do something
}
The method toHexString() returns the value of the ObjectId in a hexadecimal representation. This method may be used in the following fashion:
System.out.println( "Hex: " + anIdentifer.toHexString() );Output: Hex: ac10011c13630703111d1e027b03f692
The toString() method is used to provide a common string representation of an object. This includes display in debuggers and watch lists. To facilitate debugging and other human interaction with the Identifer, the toString() method simply returns some human-readable result and the class name. This method may be used in the following fashion:
System.out.println( anIdentifer );
Output: com.capitalstream.foundation.ObjectId:172.16.1.28-1999/6/30- 10:16:27.42-1323282
The tests above were run on more than one machine. In each case, the ObjectId generated correctly reflected the MAC address of the host on which it was generated. Therefore, by definition, running the test on multiple hosts should not produce duplicates.
The final test involved running multiple concurrent processes on the same machine. This eliminates the MAC address from the uniqueing process. To stress the algorithm, four concurrent processes were run, each generating 1,000,000 ObjectIds in as rapid a fashion as possible. Following the generation, the resulting 4,000,000 ObjectIds were examined. No duplicates were produced.
In the event that some third party product might generate a unique ID, these IDs will be treated as data, along with the other information being produced. Additionally the relationship between ObjectId and Identifier easily lends itself to a classic GOF strategy pattern should the need arise.
Finally, it is not necessary that every instance of data be stored with an ObjetId. A server log may contain sufficient information to uniquely identify every row of data. In such a case where uniqueness is inherent and access is limited to reporting and mining efforts, the storage of an ObjectId may be unnecessary overhead and dropped for space efficiency reasons.